Quality Diversity through AI Feedback

Language models carry implicit distributional biases based on their training data, which can reinforce existing norms.
See our recent update to our work here.
An edited version of the QDAIF blog, originally published here in collaboration with CarperAI and StabilityAI.
In this work, we take one step towards addressing the challenge of unwanted biases by enabling language models to return outputs with a broader spectrum of attribute traits, specified by a user. This is achieved by asking language models to evaluate and modify their outputs.
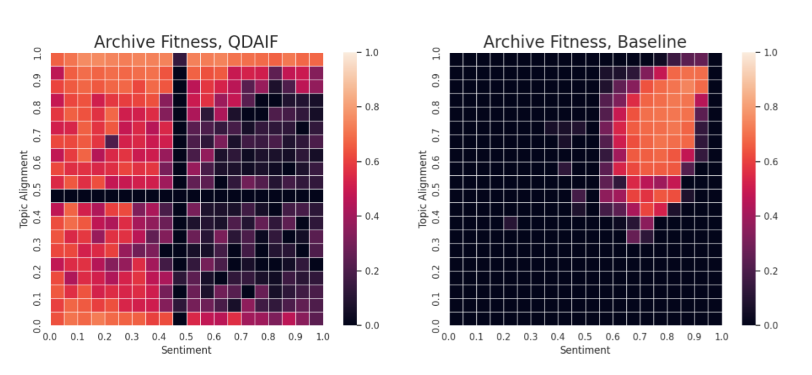
Figure 1: QDAIF increases diversity of generated outputs across user-specified traits. Maps showing the highest quality score obtained for each niche in the specified trait space (sentiment vs. topic alignment). Left: with QDAIF. Right: without QDAIF. The attribute and quality metrics are evaluated by our Luminous models. Black cells are unfilled. QDAIF sampling (left) is initialized from zero-shot movie review samples, while the baseline (right) is initialized from hand-written movie reviews. Number of inference steps used is fixed at 2000 for both.
Introduction
Language models carry implicit distributional biases based on their training data, which can reinforce existing norms. In this work, we take one step towards addressing the challenge of unwanted biases by enabling language models to return outputs with a broader spectrum of attribute traits, specified by a user. This is achieved by asking language models to evaluate and modify their outputs.
We’re excited to introduce a versatile method, “Quality Diversity through AI Feedback” (QDAIF), that allows users to sample a broad array of high-quality, creative content from language models. Through our collaboration (with pioneers in the field of open-ended AI), Luminous models were successfully integrated into an output sampling pipeline that refines text in domains such as movie reviews and short stories. Results featuring our models are showcased in our movie review writing experiments. For qualitative descriptions of outputs from our QDAIF pipeline in movie review and short story writing, please refer to the blog’s supplementary material.
Quality Diversity through AI Feedback
QDAIF is inspired by three main lines of work as part of its design: Quality Diversity algorithms (QD), Evolution Through Large Models (ELM), and AI feedback.
Along the lines of evolutionary search, QD optimizes for a diverse set of optimal solutions (typically for a hand-coded range of attribute traits), instead of a single objective solution. Recently, ELM and its follow-up work, Language Model Crossover (LMX), leverages learned priors from human knowledge to intelligently refine texts, whether it’s mathematical expressions, natural language text, or Python programs. LMX, in particular, exploits in-context learning from general-purpose LMs, and can enhance optimization using MAP-Elites, a simple QD algorithm. OpenELM, an active open-source library from CarperAI, is tailored for research on ELM, and supported by some of our researchers with existing contributions.
AI feedback is a complementary research trend that involves asking LMs for feedback on training, evaluation, or problem-solving capabilities of other LMs. Following this, Constitutional AI uses LM-generated critiques, refinements, and preference of text completions to finetune models to optimize for helpfulness and harmlessness. It is also now possible to get LMs to evaluate their own outputs, given an understanding that it’s easier to evaluate text for some quality than to generate text of this quality. Self-refine follows the idea of iterative refinement to improve on LM outputs for dialogue tasks.
QDAIF brings together quality diversity (QD), ELM, and AI feedback to augment the creativity of LMs. We first specify quality and attribute traits and determine how to prompt an LM for them. We then select an LM-based variation operator and seed the algorithm with initial solutions. Next, we establish a map from these attribute traits and start a MAP-Elites loop:
- Create offspring with the language model variation operator.
- Evaluate offspring for quality and attribute trait with the AI feedback measures.
- Replace each cell’s solution in the map with the better one.
Over time, the map is populated with diverse and high-quality solutions. This relies solely on AI feedback, eliminating the need for hand-coding quantitative quality measures or attribute traits.
We used OpenELMfor our experiments described in this blog.
Results on Evolving Creative Writing
We highlight the versatility of QDAIF through demos in movie review and short story writing.
Movie Reviews
We applied MAP-Elites to a creative writing environment where the task is to evolve movie reviews for the late 1980’s action movie “Die Hard”. We measure quality by computing the cosine similarity between the embeddings of a reference string (“Movie review for the film ‘Die Hard’”) and the generated movie review using the Luminous-Explore 13B embedding model, as a type of AI feedback on whether or not the generated text is a realistic movie review. We study diversity with respect to the generated review’s sentiment/attribute (e.g. how positive or negative a review was), by prompting an instruction-tuned model, luminous-supreme-control, to evaluate the general sentiment of the movie review text and calculating a score from log-probabilities of “positive” and “negative”.
We use our Luminous models as our language model variation operator, with LMX crossover, where each prompt consists of several movie review examples of the following form:
Here is a random example of a review for the movie “Die Hard”: {review}\n###\n
We compare our results from QDAIF against a simple baseline, which simply samples movie reviews using a fixed, hand-written 3-shot prompt. We then measure quality and diversity for each generation from the baseline, in the same manner described above, and fill out a map, calculate QD scores (defined as the sum of best solution fitness scores for all cells in the map), and compare against QDAIF.
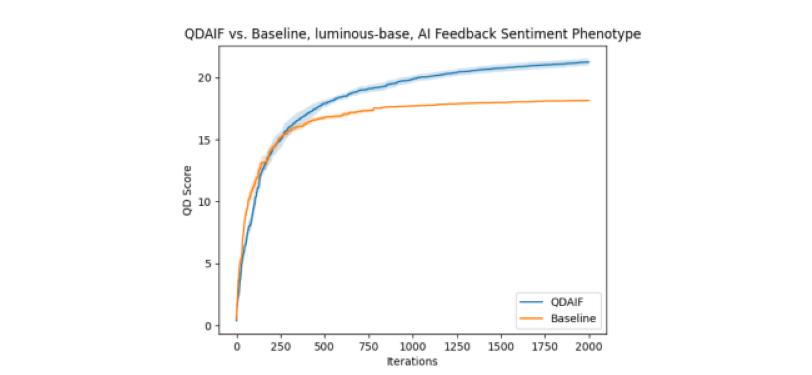
Figure 2: QD score history of comparable runs in movie review writing domain. Mean and standard error are measured in each run setting over 5 seeds.
We see notable differences in the resulting corpus of generated movie reviews between QDAIF and the baseline. Firstly, Figure 2 shows that QDAIF improves the map’s QD score more than the baseline, especially with more evolution steps. In addition, we show above some interesting qualitative results from the movie reviews discovered by QDAIF, highlighting the drive for optimization. For subjective descriptions of raw example movie reviews, please check out the supplementary material.
Interestingly, we can see that in some cases, the generated reviews converge to become more similar to the reference string used to define the fitness function, “Movie review for the film ‘Die Hard”, rather than consisting of an actual movie review:
Bin index 19/20 (positive sentiment), iteration 500:
“This is review for the movie Die Hard.”
This indicates a type of reward hacking, where the effect of optimizing the fitness function does not align with the intended goal of making texts similar to realistic movie reviews.
To study how our movie review setup generalizes to additional diversity axes, we also ran experiments with two diversity axes, adding a diversity axis to evaluate whether or not the generated movie review focuses on film characters. The overall number of niches in the resulting map is much higher than in the 1D case (400 vs 50).
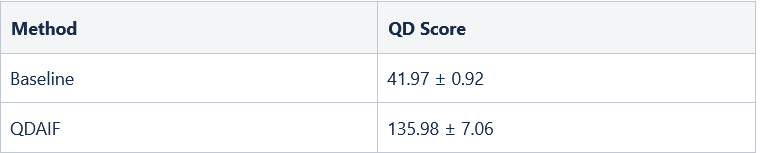
Table 1: QD score comparison from obtained 2D archives at the end of search. Mean and standard error are measured in each run setting over 5 seeds. QDAIF noticeably outperforms the baseline in discovering high-quality samples across a wider space along measures sentiment and review topic alignment.
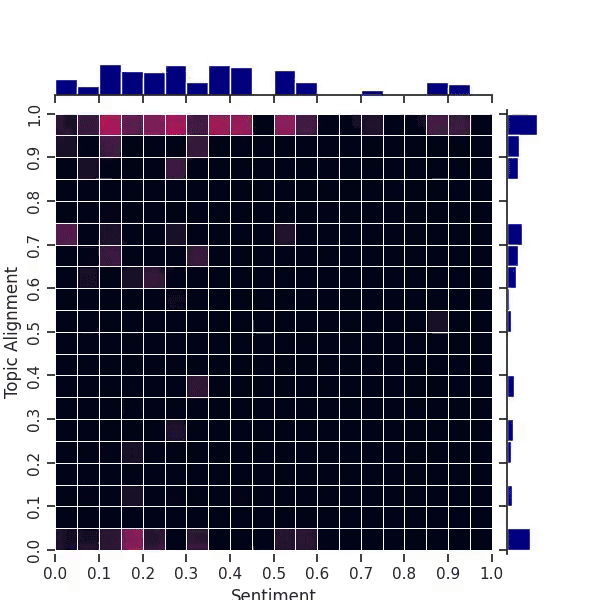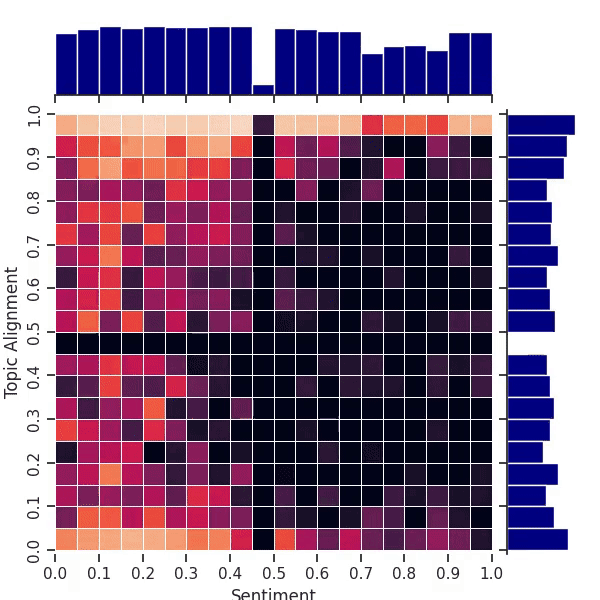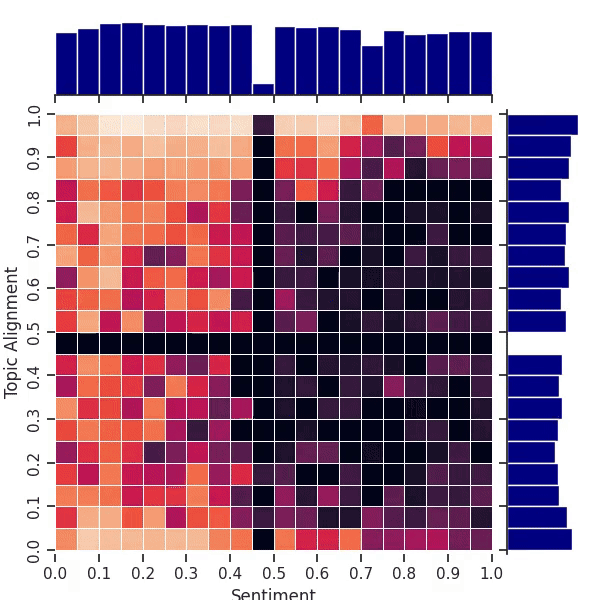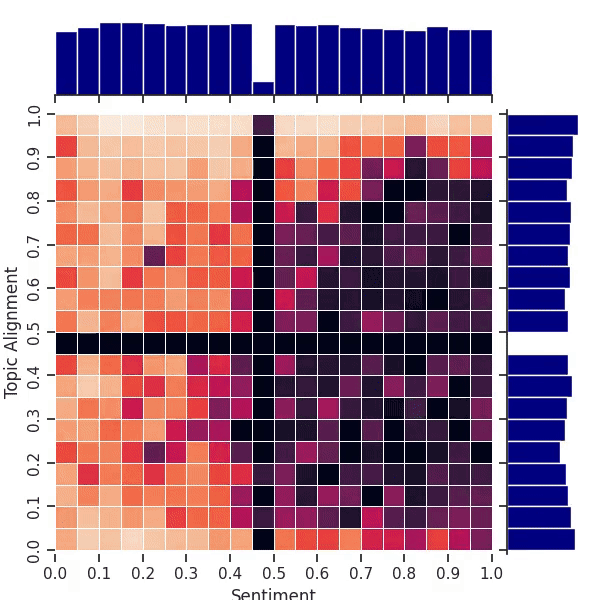
Figure 3: An animation of the map fitness improving over time on our 2D movie review task. The “cross” pattern in the center is an artifact of our use of AI feedback for sentiment and topic alignment. The archive starts out with empty black bins.
To obtain attribute feedback for this new dimension, we prompt the instruct model to evaluate whether or not the movie review focuses on film characters (by answering either “yes” or “no”). Similar to review sentiment, we compute the normalized probability of predicting an answer option to this prompt (i.e. “yes”) to compute the score.
Exploring the whole map in this case is more difficult due to the greater number of bins (400) in this 2-dimensional map. Nevertheless, the animation in Figure 3 shows that QDAIF using MAP-Elites can still successfully fill out the map with high quality examples. Figure 1 and Table 1 show how QDAIF can discover more high-quality movie review niches compared to a fitness-only optimization baseline, which fails to meaningfully optimize for diversity amongst samples.
Short Stories
To demonstrate the flexibility of QDAIF for refining creative texts, we conducted runs of evolution of short stories with varying sentiment. From excerpts in the supplementary material, we show examples on the task of short story writing containing “a suspicious spy and a rich politician”:
Bin index 2/20 (negative sentiment), iteration 100:
“The political world was highly suspicious of the politician. He was well-known for his political maneuvering and for his questionable dealings. The government was always suspicious of his actions, but they knew that he was hard to catch. He was a very shrewd person and he knew how to quickly disappear from sight.”
Bin index 2/20 (negative sentiment), iteration 400:
“The politician and the spy were waging war on each other. The politician had hired the spy to spy on the spy. The politician wanted to stay in office and make money. The spy was at the same time trying to get money out of the rich politician. The spy was also trying to get the politician arrested.“
Bin index 19/20 (positive sentiment), iteration 200:
“She was a rich politician, and I was a spy. She had a fortune, and knew it. I wanted to find out how she got her wealth, and whether or not she was hiding any dirty secrets. I was able to get some information about her in my investigation. I was about to find out some interesting information!”
The first example is missing references to the desired spy character. Despite this, a later iteration discovers a short story that is more relevant to the desired domain, with repeated references to both characters of interest. Phrases such as “highly suspicious” and “waging war” in the first two examples can be seen to have negative connotations, while phrases like “I was able to” in the third example would likely have a positive connotation. Again, we can see QDAIF uncovers a diverse set of creative texts with varying sentiments, while exploiting the fitness function to refine stories in subjectively interesting ways.
Conclusion
Quality Diversity through AI Feedback (QDAIF) is demonstrated to be a new method that exploits evolutionary search to help LMs overcome their own biases, successfully refining its outputs to discover samples across a desired spectrum of attribute traits. In addition to improving LM baseline capabilities, we believe that QDAIF could be adapted to generate finetuning data for LM self-improvement.
We plan to develop this work further into a publication—coming soon! Supplementary material to this post can be found here.
For results from our collaborators on applications of QDAIF in the domain of evolving poetry, we invite you to further explore the original blog post.
Acknowledgements
If you found this edited version of the blog post (with additional results from Aleph Alpha) insightful for your work, please cite both the original and edited versions by using:
H. Bradley, A. Dai, J. Zhang, J. Clune, K. Stanley, J. Lehman. (May 2023). Quality Diversity through AI Feedback. CarperAI Blog. https://carper.ai/quality-diversity-through-ai-feedback/
A. Dai, R. Baldock, K. Oostermeijer, H. Teufel, M. Bellagente, H. Bradley, J. Zhang, J. Clune, K. Stanley, J. Lehman. (May 2023). Quality Diversity through AI Feedback. Aleph Alpha Blog Edit. https://www.aleph-alpha.com/quality-diversity-through-ai-feedback
This work was a collaboration between CarperAI, Stability AI, and Aleph Alpha.We thank members from the Aleph Alpha research team who have contributed to the experiments and technical work using Aleph Alpha models:
- Koen Oostermeijer (visualizations and analysis)
- Marco Bellagente & Hannah Teufel (contributions and technical support for OpenELM)
- Souradeep Nanda & Jan Zierstek (general feedback and guidance)
We acknowledge the work of collaborators in this joint work:
- Herbie Bradley & Joel Lehman, for leading the overall effort on QDAIF
- Jenny Zhang, Jeff Clune & Kenneth Stanley for their work in advancing QDAIF
Authors: Andrew Dai, Robert Baldock*, Koen Oostermeijer*, Hannah Teufel*, Marco Bellagente*, Herbie Bradley, Jenny Zhang, Jeff Clune, Kenneth Stanley, Joel Lehman
*Contributed to writing the Aleph Alpha version of the blog post