Luminous-Explore – A model for world-class semantic representation

In this post we present our semantic embedding model Luminous-Explore, show state-of-the-art results on two public benchmarks and go into detail on the philosophy and practical use of semantic representations.
In this post we present our semantic embedding model Luminous-Explore, show state-of-the-art results on two public benchmarks and go into detail on the philosophy and practical use of semantic representations.
Content:
- A model for world-class semantic representation
- Semantic search with luminous models
- Benchmarks for semantic Search
- Creating semantic embeddings with luminous
- On the nature of semantic content representations
- What does a good Semantic Content Representation mean for Science, Industry, and Society?
Abstract
In this post we present semantic representations and semantic search with Luminous models. We provide two types of semantic representations: symmetric embeddings (for classification, clustering, etc.) and asymmetric embeddings (for information retrieval and context relevance). The semantic representations generated by Luminous-Explore achieve state-of-the-art performance on the USEB (5 out of 5) and BEIR (1 out of 4) benchmarks. With the provided code snippets, Luminous-Explore-generated semantic representations are open to be used by anyone. With our semantic representations we aim to make information and knowledge more accessible.
A model for world-class semantic representation
One goal of natural language processing (NLP) is the understanding of a text’s semantic meaning. Aiming at use cases like search, clustering, exploration, classification or feature extraction, researchers are striving for both high-quality and computationally efficient algorithms to understand, encode and compare meaning.
Welcome Luminous-Explore, our specially developed model for generating representations (embeddings) of text that are optimally tuned for semantic similarity. Transformer-based AI models have broken record after record in the area of NLP and are continuing to alter and shape the way we can interact and use AI in a multitude of applications. With the semantic representations generated by Luminous-Explore we contribute our part to advancing the state-of-the-art in NLP.
To create valuable semantic representations, we scaled up on the SGPT approach ([2202.08904] SGPT: GPT Sentence Embeddings for Semantic Search (arxiv.org)), which was developed as part of an internship at Aleph Alpha, to a model size of 13 billion parameters. With the resulting model we present State-of-the-Art results on their USEB and BEIR Benchmarks for semantic Search, achieving 5 out of 5 and 1 out of 5 top scores respectively.
The Luminous-Base model we fintuned with this approach, is very capable of comparing meaning on a higher, conceptual level. The capabilities of our semantic representations enable a multitude of applications to be developed on top this functionality, spanning from semantic search over guided summarisation to classification. These capabilities our publicly available over our API (Aleph Alpha API | Aleph Alpha API (aleph-alpha.com)).
Sidenote: Luminous – a family of multi-lingual Large Language Models
Luminous are a family of Large Language Models (LLM) developed by Aleph Alpha. They are capable of generating natural language in 5 different languages (English, German, French, Italian, Spanish) with state-of-the-art performance. Learn more about Luminous here: Luminous (aleph-alpha.com)

Semantic search with Luminous-Explore
With our semantic representation model Luminous-Explore built on top of the 13Bn parameter Luminous-Base LLM, we achieve state-of-the-art results compared to other LLM-based semantic representation models (Anchor benchmark subchapter).
One of the key applications of semantic representations, is semantic search, which is able to evaluate the semantic similarity of texts. By using semantic representations, we can achieve much higher scores and work with higher concepts than other, keyword-based methods. With a better search comes easier retrieval of related data and better access to information.
To understand what semantic search is and what it can do, we first need to understand how it works.
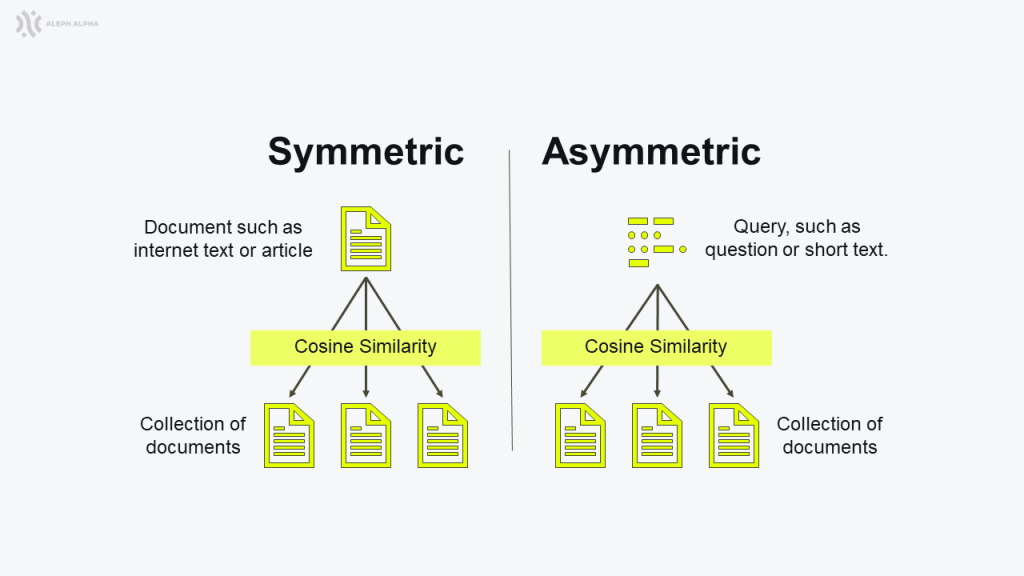
Figure 1: The difference between applying symmetric vs. asymmetric search
We can divide semantic similarity, and thereby also search, into two types: symmetric and asymmetric.
Symmetric search is when we are trying to find new texts based on similarity to a text we already have. This works especially well when we are searching texts that are not only similar semantically, but also in length, tonality, language, etc. Nevertheless, symmetric search can be used to compare any two or more texts. For semantic search we provide one model that translates all inputs into symmetric semantic embeddings.
Asymmetric search, on the other hand, is optimised to maximise similarity between two texts that are heterogenous in form. In our case, asymmetric search consists of two models: one trained to embed queries and the other trained to embed documents. The both models are optimised to generate similar representations for questions and matching texts. For asymmetric embeddings we have two separate models, one for embedding queries (short texts or questions) and one for embedding documents (longer texts, such as documents or articles).
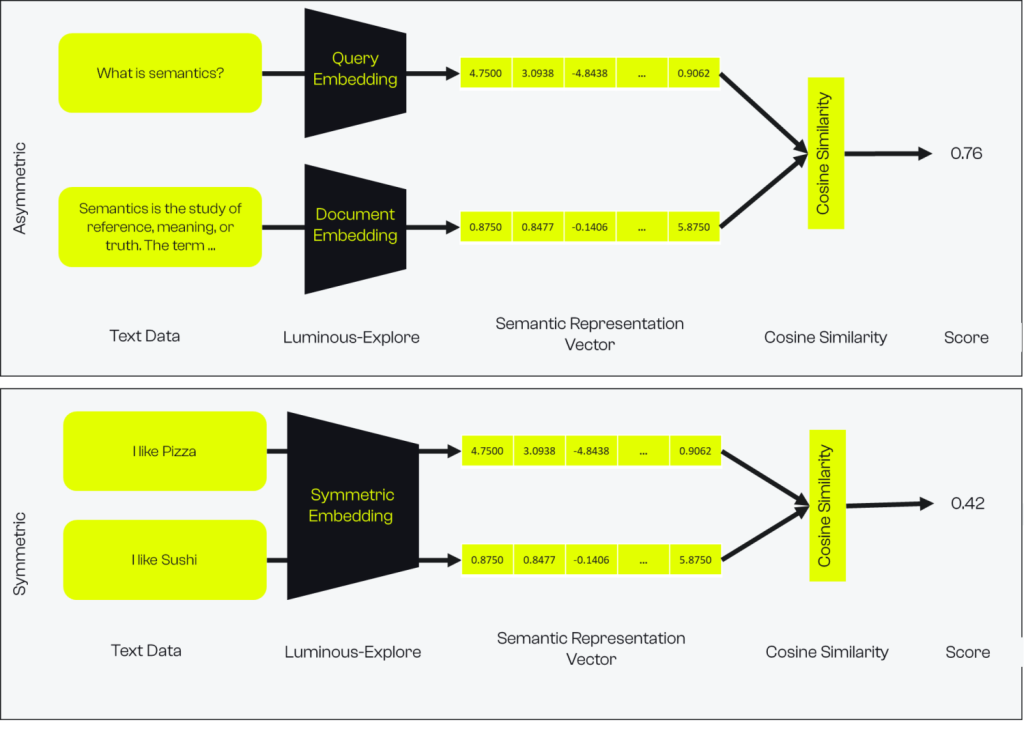
Figure 2: A schema of how scores for semantic search are calculated with symmetric and asymmetric models.
Benchmarks for semantic search
We ran common open-source benchmarks to evaluate the performance of our symmetric and asymmetric search models (described above). The results of the benchmark as well as a short description can be found below.
Symmetric Search Evaluation on USEB benchmark
Symmetric embeddings assume that the text to be compared is interchangeable. Usage examples for symmetric embeddings are clustering, regression, anomaly detection or visualisation tasks. In Table 1 you can find the evaluation scores of our symmetric search for four common datasets derived from the USEB Benchmark (GitHub – UKPLab/useb: Heterogenous, Task- and Domain-Specific Benchmark for Unsupervised Sentence Embeddings used in the TSDAE paper: https://arxiv.org/abs/2104.06979.). All four evaluate different semantic tasks. As the table shows, with our symmetric embedding model, we are able to surpass other state-of-the-art models on all four datasets. Especially on CQA and SciDocs we are able to surpass the results from OpenAI’s Curie models by 5.1% and 11% respectively.
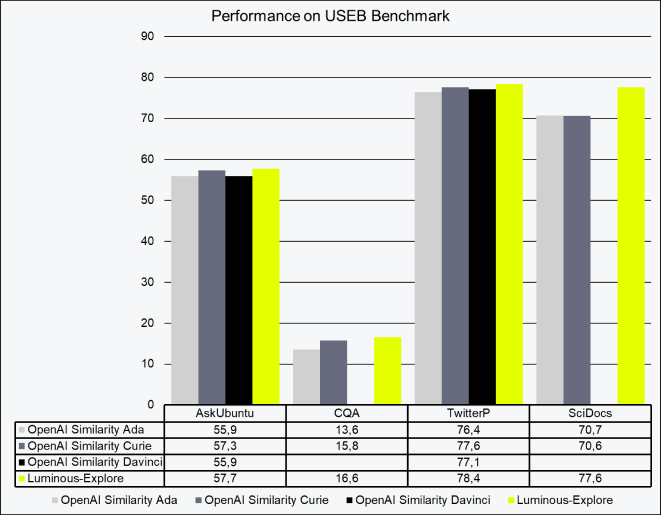
Table 1: Performance of Luminous-Explore compared to other LLM semantic representations on the USEB Benchmark. Scores are nDCG@10, values are rounded.
Asymmetric Search Evaluation on BEIR benchmark
Asymmetric embeddings assume that there is a difference in queries and documents. Usage examples for asymmetric search are search, context relevance, information retrieval. We test our asymmetric embeddings with five common datasets from the BEIR Benchmark (GitHub – beir-cellar/beir: A Heterogeneous Benchmark for Information Retrieval. Easy to use, evaluate your models across 15+ diverse IR datasets.), which can be viewed in Table 2. We can surpass current SOTA models on ArguaAna (14%) and show competitive performance on NFCorpus, SCIDOCS and SciFact.
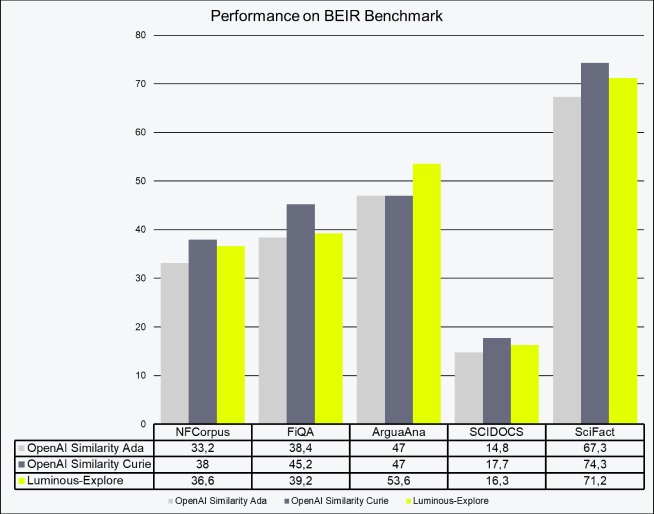
Table 2: Performance of Luminous-Explore compared to other LLM semantic representations on the BEIR Benchmark. Scores are nDCG@10, values are rounded.
Creating semantic embeddings with Luminous-Explore
Creating semantic embeddings with Luminous-Explore and using them in your own research or product is simple. This can either be done using a rest call to our API or using the pip-installable aleph-alpha-client package. Once created, embeddings can be stored locally for faster access and computation.
Here is a simple code to create a symmetric embedding for a text:
from aleph_alpha_client import AlephAlphaClient, AlephAlphaModel, SemanticEmbeddingRequest, SemanticRepresentation, Prompt import os model = AlephAlphaModel( AlephAlphaClient(host="https://api.aleph-alpha.com", token=os.getenv("AA_TOKEN")), # You need to choose a model with semantic embedding capability. model_name = "luminous-base" ) text_to_embed = "I really like Pizza." request = SemanticEmbeddingRequest(prompt=Prompt.from_text(text_to_embed), representation=SemanticRepresentation.Symmetric) result = model.semantic_embed(request) print(result.embedding)
If you want to use the embeddings for semantic search, clustering or other applications, below you can find a more detailed script on how to use the embedding API (read more in our ous Aleph Alpha API | Aleph Alpha API (aleph-alpha.com)).
""" Running this script requires the installation of the aleph alpha client. ```console pip install aleph-alpha-client ``` """ from typing import Sequence from aleph_alpha_client import ImagePrompt, AlephAlphaClient, AlephAlphaModel, SemanticEmbeddingRequest, SemanticRepresentation, Prompt import math import os API_TOKEN = "YOUR_API_TOKEN" model = AlephAlphaModel( AlephAlphaClient(host="https://api.aleph-alpha.com", token=API_TOKEN), # You need to choose a model with multimodal capabilities for this example. model_name = "luminous-base" ) # Texts to compare texts = [ "deep learning", "artificial intelligence", "deep diving", "artificial snow", ] embeddings = [] for txt in texts: request = SemanticEmbeddingRequest(prompt=Prompt.from_text(text), representation=SemanticRepresentation.Symmetric) result = model.semantic_embed(request) embeddings.append(result.embedding) # Calculate cosine similarities. Can use numpy or scipy or another library to do this def cosine_similarity(v1: Sequence[float], v2: Sequence[float]) -> float: "compute cosine similarity of v1 to v2: (v1 dot v2)/{||v1||*||v2||)" sumxx, sumxy, sumyy = 0, 0, 0 for i in range(len(v1)): x = v1[i]; y = v2[i] sumxx += x*x sumyy += y*y sumxy += x*y return sumxy/math.sqrt(sumxx*sumyy) # Cosine similarities are in [-1, 1]. Higher means more similar print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[1], cosine_similarity(embeddings[0], embeddings[1]))) print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[2], cosine_similarity(embeddings[0], embeddings[2]))) print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[3], cosine_similarity(embeddings[0], embeddings[3])))
On the nature of semantic content representations
One goal of natural language processing is the understanding of a text’s semantic meaning. Aiming at use cases like search, clustering, exploration, classification or feature extraction, researchers are striving for both high-quality and computationally efficient algorithms to understand, encode and compare meaning. Commonly, a text is converted into a semantic representation in form of a vector (list of numbers) to which mathematical operations (e.g. similarity measures) can be applied. This blogpost discusses the nature of a “good” semantic representation with regard to practical application.
A good semantic representation retains both broad and detailed information
Hypothesis: A good semantic content representation can be applied to very broad clusters and performs well on details.
A useful representation serves to differentiate occurrences within the domain or distribution of a use case. For example, a semantic representation of a broad range of tweets should identify diverse topics and opinions. One would expect generic clusters and less differentiation on a detailed level. It may be sufficient to say that the statements “The sun is shining.” and “It is raining.” are both part of the cluster “weather”. On the contrary, a specialised weather app may treat these utterances as opposites. Given that the topic is weather, a clear distinction must be made for the representation to be meaningful.
Only information related to meaning should be represented
Hypothesis: A good semantic content representation does not retain all information. Information that is unrelated to meaning should be discarded.
Paraphrases are expected to give a very similar, if not the same, semantic representation. The representation must be independent of the wording – or simply the words used could be compared. Therefore, a representation cannot be expected to be invertible, i.e. the original text cannot be reconstructed from the representation. The information is shifted into a representation which is adequate to capture the meaning. Anything unrelated is of no use and likely to be removed by an algorithm that is optimised for meaning and treats everything else as disturbing noise.
Similarity can occur in several (subjective) dimensions
Hypothesis: A single semantic representation cannot serve all possible interpretations.
Every person intuitively compares (evaluates?) statements based on their own interest and situation. Consider the following expressions:
- It is warm at my fireplace.
- It is a warm summer day.
- A frightening thunderstorm is approaching.
Which of these statements are most similar? Most likely, the warm fireplace and the warm summer day evoke a sense of well-being and relaxation. Also, the warm fireplace is probably associated with winter, whereas the other statements clearly refer to the summer.
In practice, semantic opposites are unlikely to occur
Hypothesis: Comparisons of semantic representation are always relative. Absolute values of metrics are unlikely to be meaningful.
A common metric to compare two semantic representations is cosine similarity. Mathematically this defines an opposite (a vector pointing exactly in the opposite direction). In practice, we would not expect a true opposite to occur. But what would it be? Consider the following examples:
- “The sun is shining and warm.” vs. “It is raining and cold.”: Both statements refer to the weather. They are not really opposites, but have a common theme.
- “The sun is shining.” vs. “I like my car.”: Although both statements refer to different topics, one might argue that both refer to something outside. Should they be considered opposites?
Within a specific use case one might identify opposites. At least on a philosophical level however, common characteristics can often be found in apparently diverse statements. A semantic representation that does not take such similarities into account would arguably not generalise. The same reasoning applies to negations. The sentences “I don’t have a car.” or “I have a car.” both make a statement about car ownership. They share a semantic meaning related to the topic, but with different claims at the level of detail.
This makes it difficult to compare similarity measures on an absolute level. Metrics rather compare similarities between different statements without making an absolute claim.
Text length influences semantic representations
Hypothesis: There is no generally ideal length of texts to be encoded. The use case decides.
A semantic representation encodes meaning from an arbitrary length of text. Short texts are more likely to represent concise information. Longer texts may make statements about diverse topics and may even be contradictory. Therefore, choosing the length of text (or chunk) when encoding into a semantic representation has an impact on usability. If the text is too short, it may not present enough detail for the use case. If the text is too long, no clear meaning may be presented on average. (The meaning of the text may be diluted by irrelevant details).
Information in representations should be independent of language
Hypothesis: Language, tonality and style should be ignored in semantic representations. Other representations for language, tonality, style (among others) may be adequate.
It is debatable whether language is a meaningful dimension. One may argue that meaning is independent of the language in which it is expressed. But aren’t two statements with the same meaning even more similar when expressed in the same language, potentially even using the same words? This reasoning can be extended to tonality and style. Semantic search use cases tend to ignore language, tonality and style. The aim is to find a very good match (preferably in good language), even if the search was entered without respecting grammar and spelling.
Each use case requires the use of an appropriate representation
Summary: Best results are obtained by appropriately applying symmetric or asymmetric representations to a given use case.
Not all semantic representations have the same purpose. Respective representations of different text length and language may serve different use cases. Another approach is the distinction between symmetric and asymmetric search.
Symmetric representations consider two interchangeable statements. There is no order. Common use cases are clustering, regression, anomaly detection, visualisation or feature extraction.
Asymmetric representations produce different output depending on the predefined class of a text. Common examples are queries and documents in a semantic search. A query is usually a short question (the information is explicitly unknown). A document is comparatively long and contains the answer to a query.
Sometimes meaning contains interpretation
Summary: A good semantic content representation respects context and may subject a text to interpretation to derive meaning.
Language encodes a lot of information. Simply writing down an oral statement eliminates all interpretability with regards to non-verbal communication such as tonality and facial expression. Sometimes this may even change the meaning entirely. Compare the statement “Oh, you are here again.” being expressed in an annoyed or in a joyfully surprised voice. Next to the explicit objective statement (the person seems to be in the same physical location as before), you can read more information between the lines. Without shifting the discussion from semantics to pragmatics, there is a case for the importance of indirect information like intention or emotion which may encode meaning relevant to the use case. For example, finding utterances of dissatisfaction in support chats with clients cannot (always) be based on plain vocabulary and explicit statements, but must interpret the context. The same argument applies to forgiving spelling mistakes, elaborate paraphrases or winding descriptions by non-native speakers (e.g. “This screen thing with the keyboard.” can be interpreted to refer to a laptop rather than an instrument.)
What does a good Semantic Content Representation mean for Science, Industry, and Society?
The answers to this question are numerous, diverse, and not yet determined. However, we would like to address a few areas where we see a relevant impact:
Offering more holistic approach to related work
Related work is a substantial part of every scientific endeavour, as progress is only possible when “standing on the shoulders of giants”. As of today, finding the right keywords, searching and reviewing articles is part of almost every scientific framework. Success often depends on selecting the correct technical term for the research field of interest. This is a non-trivial task for many topics (e.g. digital twin, digital shadow, digital representation, virtual twin, digital clone, virtual mirror, virtual model, …). With semantic embeddings of scientific literature, searching related work moves from creating an extensive keyword query towards a multi-facetted search that does not compare the one-dimensional matching of keywords, but can rank actual similarity on several dimensions, such as topic, intention, method, data, findings, etc.
Especially novel researchers could be helped to get an overview of a prospective research field without having to know the exact terminology or distinguished experts. This in turn might broaden and accelerate the conduct of new and innovative research for greater value creation.
Machines learning human representations vs. humans learning machine representations (beyond the keyword search)
We can see a future, where technical systems approach human representations and not vice versa.
Using approximations of semantic meaning to manage the human knowledge has been an ongoing task. Most notably through the use of artificial ontologies, keywords and categories. While systems have evolved to better represent human semantics, humans have likewise adapted to algorithmic semantics. As an example, when searching the web with a search engine, a human intention may be “what are traditional restaurants in my area that I can visit with my friends“. The query that an experienced user would type into the search engine would more likely resemble “traditional restaurants Heidelberg“. This example indicates that people align their understanding of relevant semantics with the functionality of knowledge management systems. Due to the inability of machines to create human representations, we humans have learned to represent our thoughts and intentions in machine representations.
But this is where we may be at a turning point, where we can slowly return to a more natural way of expressing our intentions through better semantic representations. This also implies that a major element of digital data management, the keywords, may become less important. While keywords can still be used as an additional metric for search, systems will not necessarily have to rely on them to perform well. The same rule applies for synonyms and antonyms or the use of technical terms.
Augmenting knowledge management with truly semantic content representation
A truly semantic content representation is one of the key technologies to uplift knowledge management from its current state. This is not only applicable for knowledge management systems of large corporations, but refers to the way knowledge is stored, managed, and retrieved throughout our society.
A knowledge management system with true semantic content representation by design can implement an interface that rather resembles asking questions to a human expert than entering keywords into a search engine. Such a system allows its users to communicate their intentions towards the system just as they would to another human. Such an interface has the potential to make knowledge more accessible to non-expert users and to help them structure their thoughts and input. Knowledge is one of the most important resources of a modern society, and facilitating access to it is a precursor to more equality in social participation and access to information.
Quick summary (by Luminous-Extended)
World-Class semantic embeddings
- Luminous-Explore is a new model for generating representations (embeddings) of text that are optimally tuned for semantic similarity.
- Aleph Alpha’s semantic representations are state-of-the-art. They enable a multitude of applications to be developed on top this functionality, spanning from semantic search over guided summarisation to classification.
Semantic Search with Luminous
- The semantic representation model is built on top of the 13Bn parameter Luminous-Base model. State-of-the-art results are achieved compared to other LLM-based semantic representation models.
- Luminous supports both symmetric and asymmetric search. Symmetric search is when we are trying to find new texts based on similarity to a text we already have. Asymmetric search is optimised to maximise similarity between two texts that are heterogenous in form.
On the nature of semantic content representations
- A good semantic representation retains both broad and detailed information.
- A good semantic content representation does not retain all information. Information that is unrelated to meaning should be discarded.
- The meaning of a statement is not only determined by the words used, but also by the context.
- Semantic opposites are unlikely to occur in practice.
- The length of texts to be encoded influences the quality of semantic representations.
- Semantic representations should be independent of language, tonality and style.
- Semantic representations are not all the same. Some are symmetric, some are asymmetric.
- A good semantic content representation respects context and may subject a text to interpretation to derive meaning.
What does a good Semantic Content Representation mean for Science, Industry, and Society?
- We can see a future, where technical systems approach human representations and not vice versa.
- Semantic content representation is a key technology to uplift knowledge management from its current state.
- A knowledge management system with true semantic content representation by design can implement an interface that rather resembles asking questions to a human expert than entering keywords into a search engine. Such a system allows its users to communicate their intentions towards the system just as they would to another human.
Authors: Samuel Weinbach & Markus Schmitz